 admin_jim 2022-03-15
admin_jim 2022-03-15
首先,明确一点,客户端(发起请求的一方),服务端(有一个服务监听着比如说8080端口)。 好,由于tcp连接四元组的定义,发起请求的一方,需要不断消耗
遇事不决祭此图:
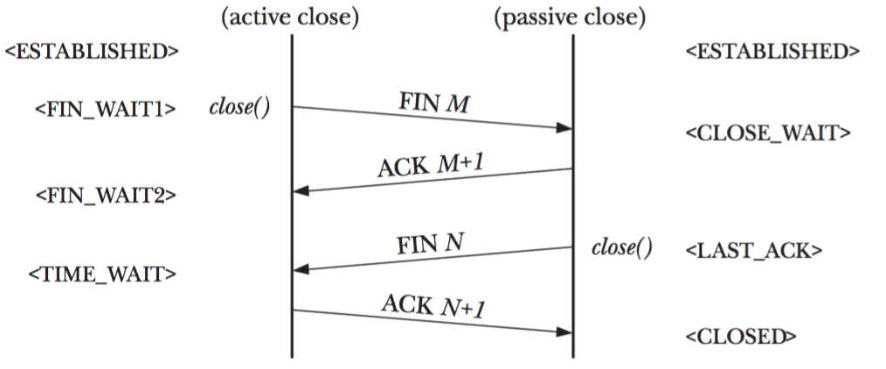
稍微补充一点是TIME_WAIT下面可以再标记一个<CLOSED>,这一步是超时自动迁移。
两条竖线分别是表示:
主动关闭(active close)的一方
被动关闭(passive close)的一方
网络上类似的图有很多,但是有的细节不够,有的存在误导。有的会把两条线分别标记成Client和Server。给读者造成困惑。对于断开连接这件事,客户端和服务端都能作为主动方发起,也就是active close可以是客户端,可以是服务端。而对端相应的就是passive close。不管谁发起,状态迁移如上图。好了开始正文:
首先题主对socket的认识存在一个常见的误区。作为服务端,不管哪个WAIT都不会耗尽客户端的端口!
举个例子,我在某云的云主机上有个Server程序:echo_server。我启动它,监听2605端口。然后我在自己的MacBook上用telnet去连接它。连上之后,在云主机上用 netstat -anp看一下:

两条记录:
LISTEN的表示是我的echo_server监听一个端口。
ESTABLISHED表示已经有一个客户端连接了。
第三列的IP端口是我server的(这个显示IP是局域网的;第四列显示的是客户端的IP和端口,也就是我MacBook。
要说明的是这个端口:31559是客户端的。这个是建立连接时的MacBook分配的随机端口。
我们看一下echoserver占用的fd。使用ls /proc/3354/fd -l (3354是echo_server的pid):
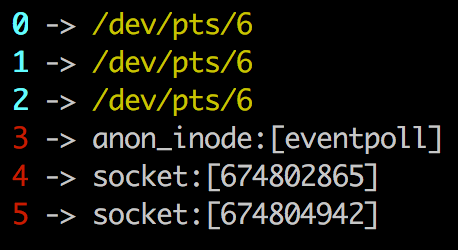
0,1,2是三巨头(标准输入,输出,错误)自不必言。3是因为我使用了epoll,所以有一个epfd。
4其实就是我服务端监听端口打开的被动套接字;
5就是客户端建立连接到时候,分配给客户端的连接套接字。server程序只要给5这个fd写数据,就相当于返回数据给客户端。
服务端怎么会耗尽客户端的端口号的。这里消耗的其实是服务端的fd(也不是端口)!
回到我的MacBook终端,查看一下2605有关的连接(Mac上netstat不太好用,只能用lsof了):

客户端pid为74135。当然,我其实知道我是用telnet连接的,只是为了查pid的话,ps aux|grep telnet也可以。
注意:为了测试。我这里的echo_server是写的有问题的。就是没有处理客户端异常断开的事件。
下面我kill掉telnet(kill -9 74131)。再回到云主机查看一下:

由于echo_server内没对连接异常进行侦测和处理。所以可以看到原先ESTABLISHED的连接变成了CLOSE_WAIT。并且会持续下去。我们再看一下它打开的fd:
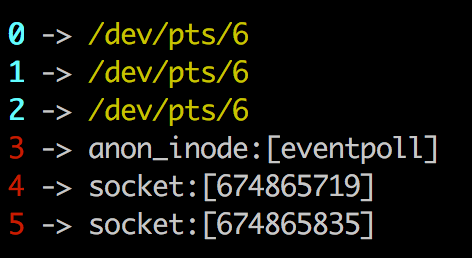
5这个fd还存在,并且会一直存在。所以当有大量CLOSE_WAIT的时候会占用服务器的fd。而一个机器能打开的fd数量是有限的。超过了,因为无法分配fd,就无法建立新连接啦!
有一个方法。比如我用了epoll,那么我监听客户端连接套接字(5)的EPOLLRDHUP这个事件。当客户端意外断开时,这个事件就会被触发,触发之后。我们针对性的对这个fd(5)执行close()操作就可以了。改下代码,重新模拟一下上述流程,blabla细节略过。现在我们新echo_server启动。MacBook的telnet连接成功。然后我kill掉了telnet。观察一下云主机上的状况:

出现了LAST_ACK。我们看下fd。命令:ls /proc/7678/fd -l
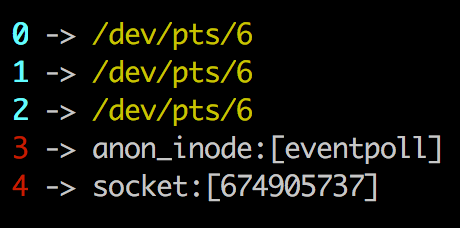
fd(5)其实已经关闭了。过一会我们重新netstat看下:

LAST_ACK也消失了。为什么出现LAST_ACK。翻到开头,看我那张图啊!
CLOSE_WAIT不会自动消失,而LAST_TACK会超时自动消失,时间很短,即使在其存续期内,fd其实也是关闭状态。实际我这个简单的程序,测试的时候不会每次都捕捉到LAST_WAIT。有时候用netstat 命令查看的时候,就是最终那副图了。
看我那个图就知道了。
现在我kill掉我的echo_server!

云主机上原先ESTABLISHED的那条瞬间变成TIME_WAIT了。
这个TIME_WAIT也是超时自动消失的。时间是2MSL。MSL是多长?
cat /proc/sys/net/ipv4/tcp_fin_timeout
一般是60。2MSL也就2分钟。在2分钟之内,对服务端有啥副作用吗?有,但问题不大。那就是这期间重新启动Server会报端口占用。这个等待,一方面是担心对方收不到自己的确认,等对方重发FIN。另一方面2MSL是报文的最长生命周期,可以避免Server重启(或其他Server绑同样端口)接收到了上一次的数据。
当然这个2MLS的等待,也可以通过给socket添加选项(SO_REUSEADDR)的方式来避免。Server可以立即重启(这样Server的监控进程就可以放心的重新拉起Server啦)。
通常情况下TIME_WAIT对服务端影响有限,而大量CLOSE_WAIT风险较高,但正确编写代码基本可以避免。为什么只说通常情况呢?因为生产环境是复杂的,一个服务通常会和多个下游服务用各种各样的协议进行通信。TIME_WAIT和CLOSE_WAIT在一些异常条件下,还是会触发的。
并不是说TIME_WAIT就真的无风险,其实无论是TIME_WAIT还是CLOSE_WAIT,永远记住当你的服务出现这两种现象的时候,它们只是某个问题导致的结果,而不是问题本身。有些网络教程教你怎么调大这个或那个的OS系统设置,个人感觉只是治标不治本。找到本质原因,避免TIME_WAIT和CLOSE_WAIT的产生,才是问题解决之道!
把这些了解清楚时候,是不是可以轻松应对什么4次挥手之类的面试题了?
![]()
写在开头,大概 4 年前,听到运维同学提到 TIME_WAIT 状态的 TCP 连接过多的问题,但是当时没有去细琢磨;最近又听人说起,是一个新手进行压测过程中,遇到的问题,因此,花点时间,细深究一下。
从这几个方面着手:
问题描述:什么现象?什么影响?
问题分析
解决方案
底层原理
模拟高并发的场景,会出现批量的 TIME_WAIT 的 TCP 连接:
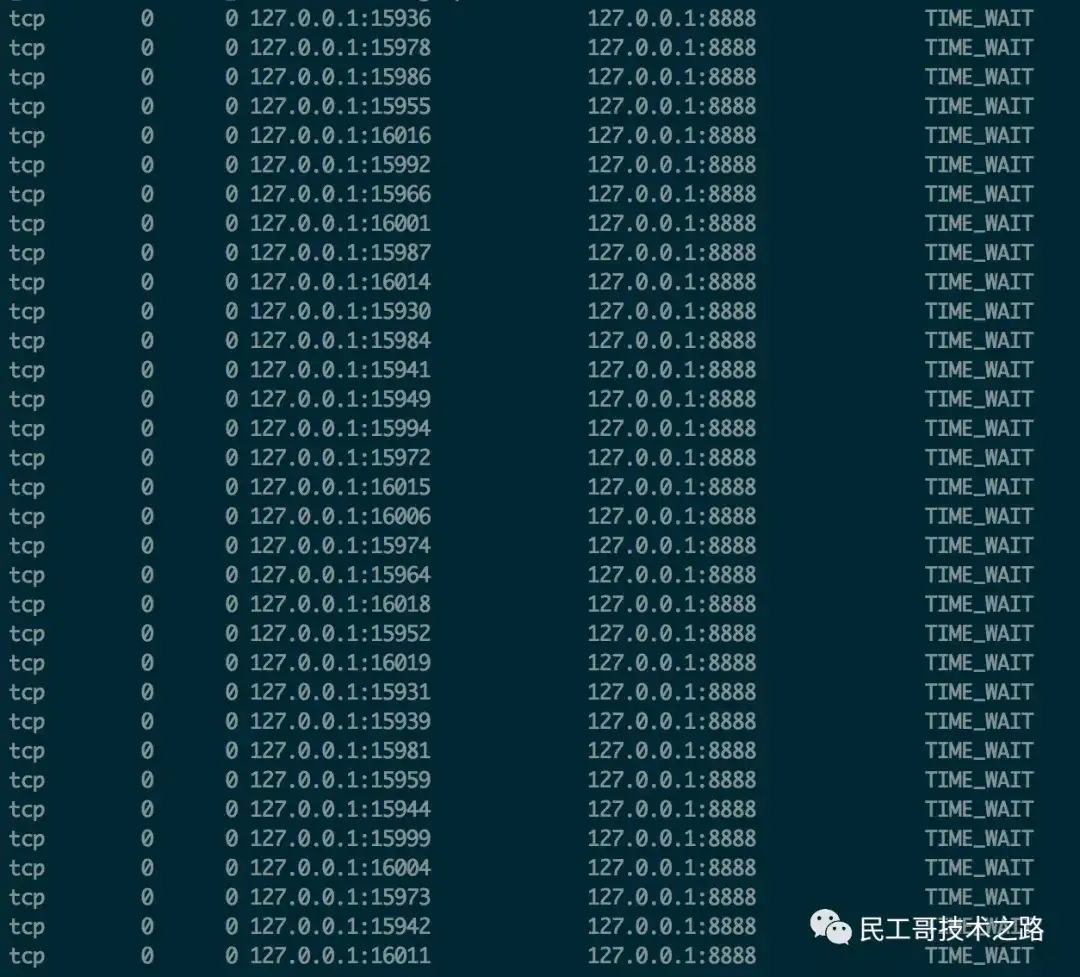
短时间后,所有的 TIME_WAIT 全都消失,被回收,端口包括服务,均正常。
即,在高并发的场景下,TIME_WAIT 连接存在,属于正常现象。
线上场景中,持续的高并发场景
一部分 TIME_WAIT 连接被回收,但新的 TIME_WAIT 连接产生;
一些极端情况下,会出现大量的 TIME_WAIT 连接。
Think:
上述大量的 TIME_WAIT 状态 TCP 连接,有什么业务上的影响吗?
Nginx 作为反向代理时,大量的短链接,可能导致 Nginx 上的 TCP 连接处于 time_wait 状态:
每一个 time_wait 状态,都会占用一个「本地端口」,上限为 65535(16 bit,2 Byte);
当大量的连接处于 time_wait 时,新建立 TCP 连接会出错,address already in use : connect 异常
统计 TCP 连接的状态:
// 统计:各种连接的数量
$ netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
ESTABLISHED 1154
TIME_WAIT 1645Tips:TCP 本地端口数量,上限为 65535(6.5w),这是因为 TCP 头部使用 16 bit,存储「端口号」,因此约束上限为 65535。
大量的 TIME_WAIT 状态 TCP 连接存在,其本质原因是什么?
大量的短连接存在
特别是 HTTP 请求中,如果 connection 头部取值被设置为 close 时,基本都由「服务端」发起主动关闭连接
而,TCP 四次挥手关闭连接机制中,为了保证 ACK 重发和丢弃延迟数据,设置 time_wait 为 2 倍的 MSL(报文最大存活时间)
TIME_WAIT 状态:
TCP 连接中,主动关闭连接的一方出现的状态;(收到 FIN 命令,进入 TIME_WAIT 状态,并返回 ACK 命令)
保持 2 个 MSL 时间,即,4 分钟;(MSL 为 2 分钟)
解决上述 time_wait 状态大量存在,导致新连接创建失败的问题,一般解决办法:
客户端,HTTP 请求的头部,connection 设置为 keep-alive,保持存活一段时间:现在的浏览器,一般都这么进行了
服务器端
允许 time_wait 状态的 socket 被重用
缩减 time_wait 时间,设置为 1 MSL(即,2 mins)
time_wait 状态的影响:
TCP 连接中,「主动发起关闭连接」的一端,会进入 time_wait 状态
time_wait 状态,默认会持续 2 MSL(报文的最大生存时间),一般是 2x2 mins
time_wait 状态下,TCP 连接占用的端口,无法被再次使用
TCP 端口数量,上限是 6.5w(65535,16 bit)
大量 time_wait 状态存在,会导致新建 TCP 连接会出错,address already in use : connect 异常
服务器端,一般设置:不允许「主动关闭连接」
但 HTTP 请求中,http 头部 connection 参数,可能设置为 close,则,服务端处理完请求会主动关闭 TCP 连接
现在浏览器中, HTTP 请求 connection 参数,一般都设置为 keep-alive
Nginx 反向代理场景中,可能出现大量短链接,服务器端,可能存在
服务器端,
允许 time_wait 状态的 socket 被重用
缩减 time_wait 时间,设置为 1 MSL(即,2 mins)
几个方面:
TCP 连接状态的查询
MSL 时间
TCP 三次握手和四次握手
Mac 下,查询 TCP 连接状态的具体命令:
// Mac 下,查询 TCP 连接状态
$ netstat -nat |grep TIME_WAIT
// Mac 下,查询 TCP 连接状态,其中 -E 表示 grep 或的匹配逻辑
$ netstat -nat | grep -E "TIME_WAIT|Local Address"
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 127.0.0.1.1080 127.0.0.1.59061 TIME_WAIT
// 统计:各种连接的数量
$ netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
ESTABLISHED 1154
TIME_WAIT 1645MSL,Maximum Segment Lifetime,“报文最大生存时间”,
任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。(IP 报文)
TCP报文 (segment)是ip数据报(datagram)的数据部分。
Tips:
RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等。
2MSL,TCP 的 TIME_WAIT 状态,也称为2MSL等待状态:
当TCP的一端发起主动关闭(收到 FIN 请求),在发出最后一个ACK 响应后,即第3次握 手完成后,发送了第四次握手的ACK包后,就进入了TIME_WAIT状态。
必须在此状态上停留两倍的MSL时间,等待2MSL时间主要目的是怕最后一个 ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后,可以再发一个ACK应答包。
在 TIME_WAIT 状态时,两端的端口不能使用,要等到2MSL时间结束,才可继续使用。(IP 层)
当连接处于2MSL等待阶段时,任何迟到的报文段都将被丢弃。
不过在实际应用中,可以通过设置 「SO_REUSEADDR选项」,达到不必等待2MSL时间结束,即可使用被占用的端口。
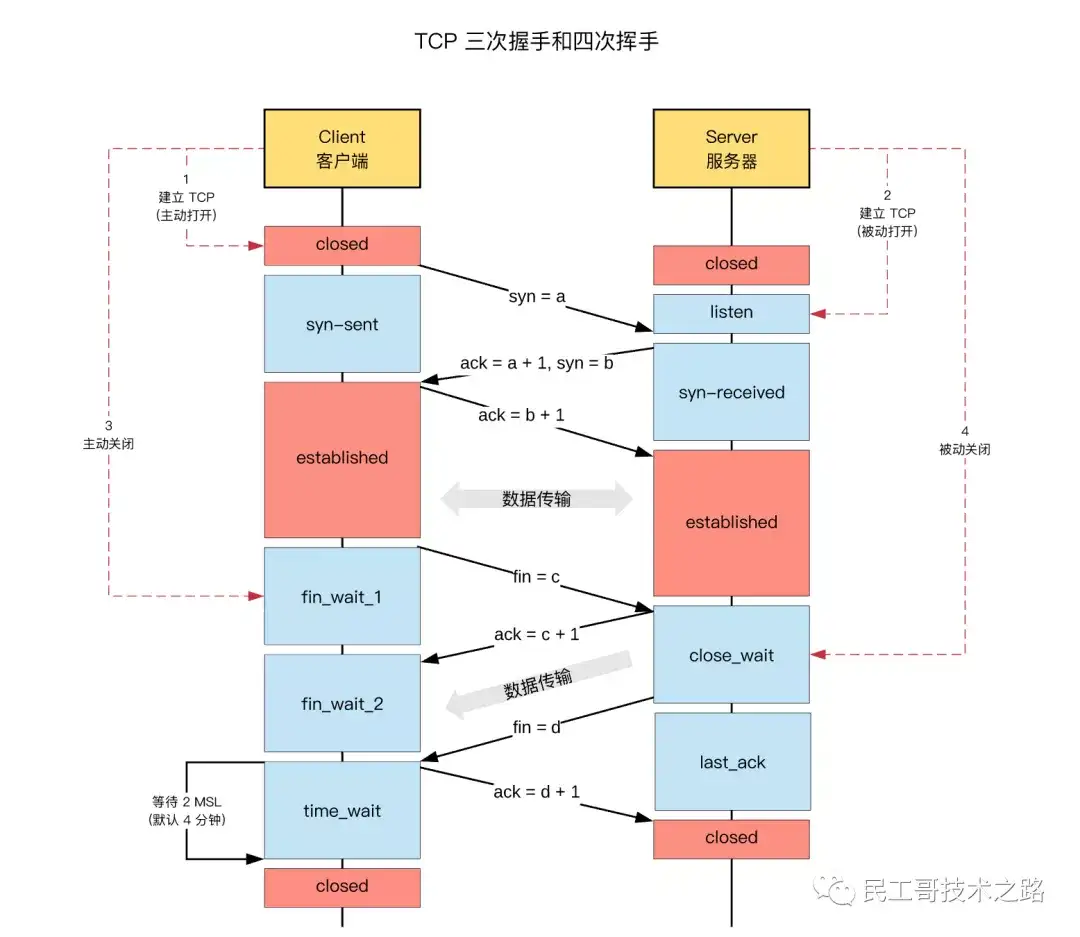
附录 C:TCP 三次握手和四次握手,详细细节,参考:TCP的三次握手与四次挥手
具体示意图:
三次握手,建立连接过程
四次挥手,释放连接过程
几个核心疑问:
RE:time_wait 是「主动关闭 TCP 连接」一方的状态,可能是「客服端」的,也可能是「服务器端」的
一般情况下,都是「客户端」所处的状态;「服务器端」一般设置「不主动关闭连接」
正常情况下,都是「客户端」发起的断开连接
「服务器」一般设置为「不主动关闭连接」,服务器通常执行「被动关闭」
但 HTTP 请求中,http 头部 connection 参数,可能设置为 close,则,服务端处理完请求会主动关闭 TCP 连接
答案是是的。在HTTP1.1协议中,有个 Connection 头,Connection有两个值,close和keep-alive,这个头就相当于客户端告诉服务端,服务端你执行完成请求之后,是关闭连接还是保持连接,保持连接就意味着在保持连接期间,只能由客户端主动断开连接。还有一个keep-alive的头,设置的值就代表了服务端保持连接保持多久。
HTTP默认的Connection值为close,那么就意味着关闭请求的一方几乎都会是由服务端这边发起的。那么这个服务端产生TIME_WAIT过多的情况就很正常了。
虽然HTTP默认Connection值为close,但是,现在的浏览器发送请求的时候一般都会设置Connection为keep-alive了。所以,也有人说,现在没有必要通过调整参数来使TIME_WAIT降低了。
TCP 连接建立后,「主动关闭连接」的一端,收到对方的 FIN 请求后,发送 ACK 响应,会处于 time_wait 状态;
time_wait 状态,存在的必要性:
可靠的实现 TCP 全双工连接的终止:四次挥手关闭 TCP 连接过程中,最后的 ACK 是由「主动关闭连接」的一端发出的,如果这个 ACK 丢失,则,对方会重发 FIN 请求,因此,在「主动关闭连接」的一段,需要维护一个 time_wait 状态,处理对方重发的 FIN 请求;
处理延迟到达的报文:由于路由器可能抖动,TCP 报文会延迟到达,为了避免「延迟到达的 TCP 报文」被误认为是「新 TCP 连接」的数据,则,需要在允许新创建 TCP 连接之前,保持一个不可用的状态,等待所有延迟报文的消失,一般设置为 2 倍的 MSL(报文的最大生存时间),解决「延迟达到的 TCP 报文」问题;
来源:ningg.top/computer-basic-theory-tcp-time-wait/
推荐阅读